¿Cómo detectar productos sin stock en un E-commerce?

La gestión del stock de los productos es uno de los conceptos más complejos de un E-commerce. Debemos tener una manera eficiente de detectar los productos sin stock que pueden impactar en la tasa de conversión y los ingresos.
Efectivamente, las fichas de productos suelen ser las páginas que más tráfico generan en un E-commerce. Además, en general tratan tráfico de calidad y bastante avanzado en el embudo de conversión.
Encontrar los productos sin stock con Screaming Frog
La manera más simple de encontrar un producto sin stock es usando Screaming Frog. En este apartado, os voy a explicar cómo hacerlo.
Etapa 1: Encontrar una página con un producto sin stock. Suele hacerse de forma rápida, ya que siempre existe por lo menos un producto sin stock en cualquier E-commerce:
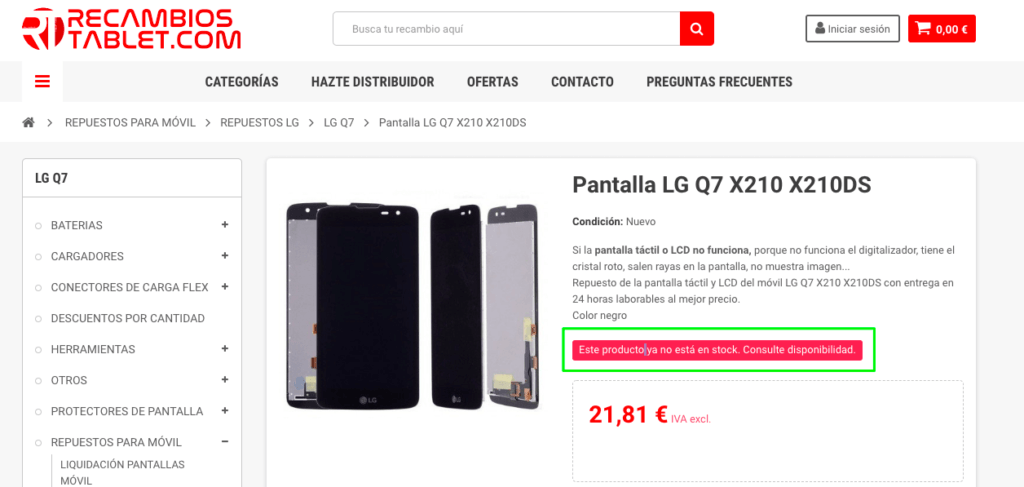
Os aconsejo que habléis con el cliente, si podéis, para que os diga cuáles son las opciones de texto que pueden aparecer en caso de que un producto esté sin stock.
Etapa 2: Copiar el texto. Os aconsejo que uséis lo que aparece en el código fuente, porque es lo que Screaming Frog usa.

Etapa 3: Abrid Screaming Frog, usad la funcionalidad de “Custom Search” y pegad el texto que hayáis copiado previamente.


Etapa 4: Podéis lanzar el crawl y esperar a que acabe para tener un listado de todos los productos que están sin stock.

Es importante revisar el listado de URLs que nos devuelve Screaming Frog para asegurarnos de que no contenga falsos positivos. Podéis también usar la funcionalidad de Custom Extraction de la rana para extraer la misma información.
Este proceso es interesante, pero tiene varias desventajas:
- Es un proceso manual, dado que tenemos que configurar Screaming Frog, esperar a que acabe y extraer los resultados.
- Rastreamos todo el portal, cuando podría ser interesante rastrear únicamente las URLs que realmente nos interesan.
Para eliminar estos dos problemas, vamos a ver cómo integrar este proceso dentro de un proceso automatizado de comprobación con Python.
Encontrar los productos sin stock con Python
En este apartado, os voy a explicar cómo podéis montar un sistema más automático con Python. Al final, lo que queremos no es obtener todas las URLs de productos sin stock (podemos llegar a tener muchas), pero sí tener un listado de URLs sin stock que hayan generado una cantidad importante de ingresos o sesiones durante las últimas semanas.
El proceso será el siguiente:
- Sacar el listado de URLs de productos que más sesiones han generado durante las 4 últimas semanas. Podríamos incluir también los ingresos pero, en este ejemplo, usaré únicamente las sesiones.
- Rastrear estas URLs para extraer el estado de stock.
- Enviar un correo con el listado de productos sin stock, ordenado por sesión.
Configuración Inicial
Primero, os indico todas las librerías que uso:
import ssl
import smtplib
import email
from google2pandas import *
from datetime import datetime
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.base import MIMEBase
from email import encoders
import time
import requests
import pandas as pd
import requests
import datetime as dt
from requests_html import HTMLSession
import xlsxwriter
Algunas de ellas sirven para enviar el correo, pero las más importantes son:
- Pandas para manipular datos.
- Googl2Pandas que la amo, porque permite recuperar datos con la API de Analytics directamente en DataFrames para después manipularlos con Pandas. Tendréis que configurar los accesos a la API de Analytics para que funcione.
- Requests y Requests_html para rastrear URLs y extraer una parte del contenido usando Xpath.
- xlsxwriter para crear archivos XLSX.
Extracción de los datos con Google2Pandas
Para extraer los datos de Analytics, podéis usar la siguiente función.
def GetAnalyticsData(ga_id, start_date, end_date):
query = {
'ids': ga_id,
'metrics': 'sessions',
'dimensions': ['landingPagePath'],
'start_date': start_date,
'end_date': end_date,
'filters': ['sessions>0'],
'max_results': 10000,
'sort': ['-sessions']
}
df, metadata = conn.execute_query(**query)
df.columns = ['pagePath', 'sessions']
# Create the full URL again
df.pagePath = 'xxxxxxx' + df.pagePath
# Merge URLs with and without parameters
df.pagePath = df.pagePath.str.replace('\?.*', '', regex=True)
aggregation_functions = {'pagePath': 'first', 'sessions':'sum'}
df_new = df.groupby(df['pagePath']).aggregate(aggregation_functions).reset_index(drop=True).sort_values(by='sessions', ascending=False)
return df_new
Lo que hace:
- Recupera el Top 10.000 de páginas durante el periodo que hayáis indicado junto con el número de sesiones asociadas para cada una de estas páginas. Como veréis, he puesto un filtro para excluir las páginas con menos de 1 sesión.
- Reconstruye la URL completa (tenéis que cambiar el ‘xxxxx’ por vuestro dominio como https://www.ejemplo.es).
- Se fusionan los datos de las URLs con y sin parámetros. Esta parte evita rastrear 20 veces la misma URL pero, si los parámetros tienen un impacto sobre el contenido de la página, no os aconsejo que la uséis.
Podéis usar más filtros e incluir más datos si fuera necesario. Para saber cuáles son los nombres de las variables, podéis usar la ayuda de Google.
Os añado unos comentarios adicionales para un mejor uso de la función:
- gaid: ID de vuestra vista en GA
- start_date y end_date tienen que tener el formato ‘AAAA-MM-DD’
Conservar únicamente las URLs de los productos
Para conservar únicamente los datos de los productos, tendremos dos opciones en función de nuestra situación:
Podemos identificar los productos con la URL
En el caso que las URLs de productos tengan un formato específico como por ejemplo: https://mipagina.es/p/mi-producto, podemos aplicar un filtro a lo que nos devuelva la API de Google Analytics sin ningún problema.
data = GetAnalyticsData(ga_id, start_date, end_date)
data = data[data['pagePath'].str.contains('/p')]
Fácil y rápido, como me gusta. Sin embargo, no os voy a engañar: casi nunca se puede usar este método y tenemos que ser un poco más creativos.
No podemos identificar los productos con la URL
En este caso, no existe un solo método, pero la idea es encontrar algo en el código que nos permita asegurarnos que la URL es de un producto. En el código que os indico a continuación, estamos en esta situación y se extrae esta información del DataLayer que usa Google Tag Manager.
Recuperar el estado de stock de nuestros productos
Primero el código, después la explicación 🙂
urls = data['pagePath']
output = [['pagePath','stock']]
for element in urls:
r = session.get(element)
# Xpath + extracción del page_type
page_type = r.html.xpath('//script/text()')[0]
page_type = pd.Series(str(page_type))
page_type = page_type.str.replace(
'.*dataLayer.*pageType\"\:\"', '',
regex=True).str.replace('\"\,\"pageUrl.*', '', regex=True)
page_type = page_type[0]
if page_type == 'product':
try:
stock = r.html.xpath('//button[@id="add-to-cart"]/text()')[0]
except:
stock = 'Error extrayendo los datos'
output.append([element,stock])
i += 1
print('Success for element ' + str(i) + ' out of ' + str(len(urls)))
final = pd.DataFrame(output[1:],columns=output[0])
final = final.merge(
data, on='pagePath', how='left')
final = final.sort_values(by=['sessions'])
# Create a Pandas Excel writer using XlsxWriter as the engine.
writer = pd.ExcelWriter('output.xlsx', engine='xlsxwriter')
final.to_excel(writer, sheet_name='data')
# Close the Pandas Excel writer and output the Excel file.
writer.save()
- Primero, se crea la variable ‘urls’, que es un listado de todas las URLs que vamos a rastrear.
- Se rastrean las URLs una por una y, si el pageType del DataLayer corresponde a “product”, entonces se extrae el estado del stock gracias a su Xpath.
- Creamos una tabla que tiene esta estructura:
| URL | STOCK |
| https://ww.ejemplo.es/producto-1 | En Stock |
Y que fusionamos con nuestra tabla inicial, que tenía esta estructura…
| URL | Sesiones |
| https://www.ejemplo.es/producto-1 | 1456 |
… para obtener la siguiente tabla final:
| URL | Sesiones | Stock |
| https://www.ejemplo.es/producto-1 | 1456 | En Stock |
Vamos, que hemos hecho un BuscarV 🙂
- Finalmente, guardamos los resultados en un archivo Excel. Podríamos guardar únicamente los resultados de los productos sin stock pero, en este caso, hemos decidido guardar todo por si acaso.
Envío del correo
Esta parte del código es la más importante, porque es lo que nos permite automatizar todo el proceso. En efecto, si subimos nuestro script Python a un servidor y creamos una tarea CRON para que se ejecute, por ejemplo, una vez a la semana, recibiremos un correo una vez a la semana con el estado de stock de nuestro E-commerce con las sesiones asociadas. Genial, ¿no?
Para esta parte, os aconsejo que miréis https://realpython.com/python-send-email/ de dónde he sacado el código que uso. Tengo ciertos conocimientos de Pyhton, sobre todo enfocados a analizar datos y, la verdad, es que la parte de E-mail se me escapa un poco.
Conclusión
Como habréis visto, existen varias maneras de extraer el stock de vuestro E-commerce, pero sin tener en cuenta el método que uséis, os aconsejo que lo miréis de vez en cuando, porque sin stock no se puede vender nada con un E-commerce.
Últimas Entradas

Cómo utilizar Google Search Console y ScreamingFrog para realizar una auditoría técnica de tu dominio
Usando APIs para conectar Google Search Console con ScreamingFrog Esta es la segunda guía sobre…

El arte de medir el éxito de un blog en GA4. Estrategias y Herramientas
En el artículo de hoy vamos a ver cómo resolver un gran problema que tienen…

SEO para aseguradoras: Cómo posicionarte en Google en este competido mercado
En el momento en el que queremos seguir una estrategia de posicionamiento orgánico dentro del…

Pasos clave para alinear tu estrategia de SEO con las diferentes etapas del funnel de ventas
1 Qué es una estrategia SEO Una estrategia de SEO (Search Engine Optimization, por sus…

Paso a paso para crear un Buyer Persona para una estrategia SEO
En el mundo digital, el éxito de una estrategia de marketing depende en gran medida…

Todo lo que debes saber sobre las campañas de Performance Max y nuestra experiencia con ellas
En el mundo del marketing digital, las campañas publicitarias se han vuelto cada vez más…

Inteligencia artificial y SEO: cómo las herramientas de IA están revolucionando las estrategias SEO
La inteligencia artificial está transformando radicalmente el panorama del marketing digital, y el SEO no…

Cómo utilizar Rich Snippets en su sitio web usando JSON
Lo importante que es destacar en los resultados de búsqueda es evidente para aquellos que…

Cómo definir tus objetivos de marketing y KPIs para medir el éxito
La definición de objetivos medibles y KPIs es de vital importancia para cualquier negocio, ya…

La estrategia de campañas de pago con la que logramos records de venta en el cliente Plykit
En el competitivo mundo del marketing digital, las campañas de pago se han convertido en…

Cómo aumentar la media de páginas visitadas por usuario
Teniendo en cuenta que atraer tráfico a tu web requiere un considerable esfuerzo, también es…

Canva + Chat GPT para crear reels de instagram rápidos para usar en campañas de pago
Hoy te queremos explicar cómo crear un reel de Instagram de manera rápida usando Canva…

Guía de Google Search Console: secretos sobre el análisis de rendimiento
Esta es la primera parte de una serie completa de artículos sobre Google Search Console…

¿Funciona el marketing de influencers en la actualidad?
El uso del marketing de influencers ha aumentado de forma exponencial en la última década…

Cómo desarrollar una buena estrategia de UX
En el competitivo mundo digital actual, una estrategia de UX bien diseñada es fundamental para…

Revoluciona tus Campañas de Paid Media con Herramientas IA: Innovación y eficiencia en la estrategia de PPC
La inteligencia artificial está cambiando el marketing digital, especialmente las campañas de pago por clic…

Cómo crear tu propia extensión en Google Sheets para Chat GPT (Usando Chat GPT)
En este post veremos cómo hacer tu propia extensión en Google Sheets! Sí, sí, como…

Qué es un soft 404 y por qué puede impactar en tu SEO en 2024
En un reciente post en Linkedin Gary Illyes ha informado acerca de los errores soft…

Influencer Marketing para SEO: Cómo aprovechar el poder de los influencers
Ya hemos hablado de la importancia de incluir campañas con influencers en tus estrategias de…

Tutorial de la herramienta SEO SE Ranking
Un SEO de nuestro equipo de explica todo lo que necesitas saber para configurar un…

Cómo mejorar el rendimiento de tu web
Uno de los primeros obstáculos que enfrenta un usuario cuando accede a tu web es…

Google se carga el scroll infinito en los resultados de búsqueda
Casi 4 años después Google ha decidido eliminar el scroll infinito de los resultados de…

Cómo crear una newsletter de éxito que ayude a tu negocio
En el competitivo mundo del marketing digital, las newsletters se han convertido en una de…

Cómo saber cuando visitó Google tu web por última vez con Screaming Frog
En nuestra agencia SEO amamos con todo nuestro corazón a la ranita. Nos referimos a…

Cómo pasar el test de Core Web Vitals de Google en tu web
Un brand book es un documento que reúne todas las directrices y estándares visuales y…

Brand book. ¿Por qué tu marca necesita uno y cómo crearlo?
Un brand book es un documento que reúne todas las directrices y estándares visuales y…

Estudio Linkbuilding. El 96.3% de las webs en el top 10 tienen más de 1.000 enlaces únicos
Muchas veces en nuestra agencia SEO los clientes nos han preguntado si realmente el linkbuilding…

Google publica un post con preguntas frecuentes sobre Google AI Overviews
Google acaba de publicar en un post de los foros oficiales en support.google.com las preguntas…

La herramienta SEO SE Ranking analiza los cambios de las SERPs con las nuevas AI overviews.
La herramienta SEO SE Ranking ha publicado en su blog un estudio analizando el antes y después…

Cómo tener las mejores biografías de autor en tu blog o web
Una parte muy importante de la estrategia de contenidos es contar con una buena biografía…

SEO para medios. Nuestro caso de éxito con Marketing4all
¿Quieres saber como conseguimos en SEOCOM un crecimiento en clics de alrededor del +180% en…

Cómo posicionarse en Google: Todo lo que debes tener en cuenta
Si has llegado a este artículo seguramente ya conozcas lo importante que es para un…

La estrategia de contenidos con la cual hicimos crecer a Giorgi un +1000%
En el competitivo mundo digital actual, aumentar el tráfico orgánico y la visibilidad de un…

Seo para inmobiliarias
Encontrar y contratar expertos en el sector SEO inmobiliario es fundamental ya que los usuarios…

Cómo utilizar el SEO para atraer talento a tu empresa.
En un mercado laboral cada vez más digitalizado y dinámico, la capacidad para atraer talento…

Cómo visualizar los datos de tus proyectos de Marketing Digital
Hoy en día, para un negocio contar con datos reales es de vital importancia, ya…

Guía completa para hacer publicidad en YouTube
Crear una campaña en YouTube es relativamente sencillo pero debemos saber configurar óptimamente la campaña…

Los mitos comunes sobre el SEO que debes dejar de creer
Nunca está de más desmentir algunas de las ideas falsas o equivocadas que muchos tienen…

Los secretos del algoritmo de Google se filtran ¿Cambiará el SEO a partir de ahora?
El mundo del SEO y del Marketing Digital se ha visto revolucionado por la supuesta…

SEO para casinos: Los 8 tips imprescindibles para una estrategia SEO que triunfe
En este artículo, te ofrecemos una guía detallada para optimizar tu sitio de apuestas o…

Cómo crear contenido optimizado para motores de búsqueda sin sacrificar la calidad
A la hora de redactar contenido, frecuentemente nos encontramos ante un dilema: ¿es posible escribir…

Cómo optimizar las fichas de producto de tu ecommerce: Guía 2024
Guía sobre las fichas de producto en 2024 para ecommerce Las fichas de producto de…

Cómo el SEO puede impulsar las ventas de tu empresa
Relación entre el SEO y las ventas de tu empresa En el mundo del comercio…

Qué es una Auditoría SEO y cómo llevarla a cabo en el 2024
En este artículo te contamos todo lo que necesitas para entender la importancia y cómo…

Bloquear el acceso de Ai Overviews . Google actualiza su documentación
La reciente actualización de la página de documentación oficial hace referencia a varias novedades sobre…

Cómo optimizar contenidos para la búsqueda por voz en 2024
Las búsquedas por voz están transformando radicalmente la manera en que los usuarios interactúan con…

Errores web | 404, 403, 503, 502, 401.. | Significado y soluciones
En otros post como este sobre el error 500 en Wordpress hemos abordado el tema…
Más IA en el buscador de Google con el anuncio de Ai Overview
De todos los anuncios que hemos visto en el eventazo del Google I/O de 2024…

Revoluciona tu SEO con las entidades. Más allá de las palabras clave
El término entidades y entidad se ha vuelto súper popular en el sector del SEO…

Cómo conectar Screaming Frog con ChatGPT para utilizarlo en tus crawls
La última versión de Screaming Frog es la bomba. La inclusión de Javascript personalizado para…

Cómo conseguir que Chat GPT recomiende tu marca
Es una realidad que cada vez más personas utilizan Chat GPT como un buscador. Teniendo…

Cómo analizar la competencia SEO con Sistrix
El análisis de la competencia SEO resulta un proceso fundamental cuando estamos tratando de auditar…

Guía Definitiva para crear un Embudo de Ventas en Google Ads
El embudo de ventas representa el viaje del cliente desde el conocimiento de la marca…

Universal Analytics dejará de funcionar a partir del 1 de julio del 2024. ¿Cómo prepararse?
El 1 de julio del 2024, las propiedades de Google Analytics 4 habrán sustituido por…

Creadores UGC: qué son y qué los diferencia de los influencers
Un estudio realizado por Harris Interactive dice que el 90% de los consumidores toma decisiones…

Sistrix: mejores herramientas SEO
En el mundo del SEO, las herramientas son un factor decisivo para poder ofrecer los…

Cómo crear contenido Evergreen que atraiga tráfico a tu web a largo plazo
Dentro de la creación de contenidos para tu página web, una de las estrategias más…

Qué es Google Discover y cómo usarlo
En el dinámico entorno digital, caracterizado por un flujo constante e incesante de datos, la…

¿Cómo optimizar tus contenidos con Search Generative Experience?
La constante búsqueda de innovación y adaptación define el éxito de las estrategias implementadas por…

Comment marketing: ¿Sabes lo que es?
¿Sueles comentar publicaciones en redes sociales? Si no lo haces, quizás deberías replanteartelo. El comment…

SEO tip estratégico: optimizando conversiones con datos de Paid
Algunos de los más puristas siempre dirán que el SEM (Search Engine Marketing) engloba tanto…

Qué es Search Intent o Intención de Búsqueda
En este artículo veremos qué es el Search Intent, también llamado Intención de Búsqueda. Este…
Nuevo Google Core Update con nuevas políticas anti spam
Google ha anunciado el 05 de marzo un core update con el objetivo de limpiar…

Gartner predice una caída de búsquedas en Google del 25% en 2026 por la IA
Gartner, una prestigiosa empresa de publicaciones y estudios, ha pronosticado recientemente la caída en el…

Google Premier Partners 2024: ¿Qué es?
Recientemente, en SEOCOM hemos vuelto a convertirnos en Premier Partners de Google para este 2024.…

Google PageRank – Datos y curiosidades
PageRank, literalmente “posición de la página” viene del nombre de Larry Page, quien junto con…

Un estudio alerta sobre el impacto de Google SGE en el sector travel
Un reciente estudio de Peak Ace, una agencia alemana, ha explorado recientemente el impacto del…

Informes SEO y LINK BUILDING en Google Analytics 4
Los informes de Google Analytics 4 que os presentamos a continuación pueden ayudaros a visualizar…

¿Qué es el snackable content?
Este enfoque, cada vez más adoptado por marcas y creadores de contenido, es un pilar…

Google compra acceso a Reddit. ¿Veremos todavía más contenido de Reddit en Google?
Si ayer hablábamos de un estudio sobre el contenido de Reddit en los resultados de…

Google lanza nuevos datos estructurados de producto. Las variaciones de producto
Los datos estructurados de producto, que ya son uno de los datos estructurados más completos,…
El Adiós a las Campañas de Discovery Ads y la Bienvenida a la Era de Demand Gen
En el cambiante mundo del marketing digital, la adaptación y la evolución son clave para…

Meme marketing: cómo usarlo para tu estrategia digital
Hoy en día, todos estamos buscando esa chispa que haga que nuestras estrategias digitales destaquen…

Cómo iniciar una campaña de mailing exitosa
Si estás dando tus primeros pasos en la creación de campañas de mailings desde cero,…

Pain Point (o puntos de dolor) de un cliente. Así puedes identificarlos
En el amplio mundo del marketing digital, existen muchos factores a tener en cuenta para…

¿Qué es flexbox y cómo utilizarlo?
Flexbox, o Flexible Box Layout, es un modelo de diseño CSS que proporciona una forma…

SEO semántico: qué es y cómo hacer una estrategia
Las palabras son muy importantes en el SEO. Pero igual de importante es su significado.…

Mejores herramientas SEO para 2024
¿Cuáles son las mejores herramientas SEO que puedes utilizar hoy en día?Solo hace falta buscar…

Qué es el EEAT en SEO: guía para optimizarlo
Navegar por el océano del posicionamiento en buscadores puede parecerte una tarea desalentadora. Sin embargo,…

Diseño web responsive con Tailwind CSS
El diseño web responsive se ha convertido en una parte fundamental del desarrollo web en…

Servicios de posicionamiento y SEO. Lo que necesitas y lo que no
A la hora de contactar con una agencia de SEO para solicitar un servicio, la…

¿Qué es el marketing de contenidos?
Content Marketing o Marketing de Contenidos… Este último año hemos oído este término muchas veces,…

Licensing vs Merchandising: ¿conoces las diferencias?
En el mundo del entretenimiento, la venta de productos relacionados con la ficción o con…

Google presenta «Circle to Search» y «Multisearch». Nuevas maneras de buscar en Android
Google ha presentado recientemente dos novedades para los usuarios de móviles y tablets con sistema…

Google se está cargando a los Quality Raters. ¿La IA tomará el control?
La semana pasada saltaba la noticia. Google está finalizando contratos con las empresas de terceros…

La batalla de los contenidos cortos: TikTok vs YouTube
La competencia en el mundo de las redes sociales ha alcanzado nuevas alturas con la…

¿Conoces el Dark Social?
Los hábitos de los usuarios online se están transformando igual que cambia el funcionamiento de…

Aparecer primero en google. Comparamos recomendaciones de chatBOTS. ¿Los nuevos reyes del SEO?
A pesar de que en SEOCOM somos expertos en SEO a nivel profesional, no ignoramos…

De lead a cliente: Claves para lograr una venta
¿Cómo lograr una venta?Lograr la venta de un proyecto depende de la calidad con la…

Branded Content: todo lo que necesitas saber sobre contenido de marca
¿Por qué ciertas marcas nos vienen a la cabeza cuando nos mencionan un tipo de…

Cómo bloquear el acceso de los bots de IA a tu sitio web
En el lado técnico de tu estrategia de contenidos , la protección de tu página…
Novedades en el SEO local de Google para este año
El SEO local va a seguir siendo este año un pilar fundamental en la mayoría…

Pinterest España: la tendencia para este 2024
La conversación del 2023 estuvo alrededor de TikTok, de cómo las marcas tenían que sumarse…

¿Has oído hablar sobre el FOOH?: la nueva tendencia publicitaria de lo más futurista
En los últimos meses, las grandes compañías han empezado a apostar por anuncios de lo…

Rankings orgánicos de Google y de Google SGE no coinciden el 94% de las veces. Houston, ¿tenemos un problema?
Un reciente estudio publicado sobre el impacto de SGE en los rankings de los resultados…
Análisis de Sentimiento en SEO. ¿Sirve de algo? Usos y herramientas
¿Cómo saber si estamos llegando y conectando con nuestra audiencia a un nivel emocional, más…

¿Son las menciones de marca el nuevo linkbuilding?
Conseguir enlaces para tu sitio web puede ser una tarea ardua y costosa. Muchos profesionales…

El papel del SEO en SGE. ¿El nacimiento del SGEO?
El impacto del nuevo motor de búsqueda de Google, SGE, tendrá unos efectos notables en…

Marketing conversacional: ¿lo conoces?
Marketing conversacional: ¿lo conoces?

Google confirma que el horario de tu negocio tiene impacto en el SEO local y Google Maps
Algunos profesionales del SEO han descubierto recientemente que Google ha reajustado sus algoritmos de búsqueda…

¿Puede el blog de tu empresa aparecer en Google News?
Google news puede ser una muy buena fuente de lectores y usuarios para tu blog.…

Storyselling: vender contando historias
Si no lo has escuchado todavía, el storyselling, o vender a través de contar historias,…

Marketing digital: Claves para afrontar el 2024
Desde luego, viene un año lleno de cambios y novedades por delante. Pero no hay…

NurIA: la influencer virtual experta en marketing
Pese a que suena todavía lejano, crear contenido con inteligencia artificial ya es algo muy…

El éxito detrás del marketing de influencers
Si estás buscando generar conexiones significativas con tu público objetivo, crear una campaña con influencers…

SEOcrawl: el software para Reporting y Business Intelligence
Todo experto en SEO que se precie debe trabajar con las mejores herramientas, como es…

La transparencia en el trabajo de una agencia SEO
Cuando se trata de mejorar la visibilidad de una página web,contratar a una agencia de…

Introducción al Content Marketing: por qué es esencial para tu estrategia digital
En este artículo, exploramos la importancia del Content Marketing en tu estrategia digital y cómo…

Las claves del SEO en 2023: últimas tendencias y actualizaciones
Descubre las últimas tendencias y actualizaciones en SEO para el año 2023. Conoce las claves…

Redacción SEO. Una herramienta potentísima que no estas usando. Sistrix Content Assistant
Una de las mejores maneras de incrementar tu tráfico orgánico es a través de la…

Aprende a analizar el perfil de enlaces de una web con Sistrix
Bienvenidos una vez más al blog de SEOCOM. En esta ocasión, vamos a hablar sobre…

¿Qué es una migración SEO y qué aspectos debemos tener en cuenta?
Las migraciones de sitios web son seguramente una de las tareas más sensibles de ejecutar…

Saca provecho a tus análisis de palabras clave con Sistrix
¿Quieres optimizar tu estrategia SEO y mejorar tu posicionamiento en los motores de búsqueda? Entonces…

Estrategias para mejorar el SEO a través de las redes sociales
Las redes sociales son una herramienta muy poderosa de estrategia de marketing para mejorar el…

Crear un status de proyecto web con Sistrix
Hoy venimos a hablaros sobre como conocer el estado SEO de un proyecto, qué debemos…

Etiqueta rel=“Canonical” en SEO: Qué es y cómo usarla de forma correcta.
Este post, vamos a hablar sobre la etiqueta Rel="canonical", y vamos a mirar de explicarte…
Controla tu proyecto web con Sistrix Optimizer
Como ya sabemos, Sistrix es una herramienta muy potente, y una de las favoritas de…

SEO para SAAS
¿Cuál puede ser la estrategia secreta que hace que una herramienta de diseño gráfico online…

iMacros: Una herramienta para automatizar tareas en 2023
Si quieres ahorrar tiempo con tus tareas repetitivas con el navegador, en Seocom te explicamos…
Extensiones de anuncio en Google Ads. Actualizado [2023]
Si tienes creadas campañas en Google Ads y necesitas mejorar el CTR de tus anuncios…

Seo para imágenes. Básicos que no puedes olvidar
Las imágenes e infografías son de gran importancia en el diseño web, ya que es…
▷ Extensiones SEO para Google Chrome imprescindibles
En todo proyecto digital, es de gran importancia la parte que implica el SEO. Por…

Error 500 en WordPress: Causas y soluciones
¿Estás experimentando algún error de WordPress o te has encontrado con la página en blanco…

Microinfluencers y nanoinfluencers. ¿La solución que estás buscando?
¿Trabajar con todos los tipos de influencers ayudará a tu plan de marketing? La respuesta…

SEO para blogs: Cómo optimizar tus publicaciones
WordPress es sin duda el rey de los CMS. Aproximadamente un 20% de las webs…

Las 5 claves para un buen SEO local
Principalmente vamos a empezar por las preguntas más concretas: ¿Qué es el SEO local? El…

Cómo insertar marcado Schema en WordPress
Si has llegado hasta aquí significa que estás intentando pulir tu SEO para llevarlo a…

Descubre cómo crear un mapa de contenidos en 6 sencillos pasos
Un mapa de contenidos (también conocido como content mapping), nos sirve para saber con exactitud…