
Product inventory management is one of the most complex facets of an E-commerce. We must have an efficient process to detect out of stock products which may lead to lost sales and impact our revenue.
Indeed, product pages are usually generating the majority of incoming traffic for E-commerce. Moreover, it’s often relevant traffic, in the bottom neck of the conversion funnel.
Find out of stock products with Screaming Frog
The simplest way of finding an out of stock product is using Screaming Frog. In this section, I’ll explain how to do it, step by step.
Step 1: Find a page with an out of stock product. It shouldn’t be that hard, as you always have at least one in any E-commerce you can come upon.
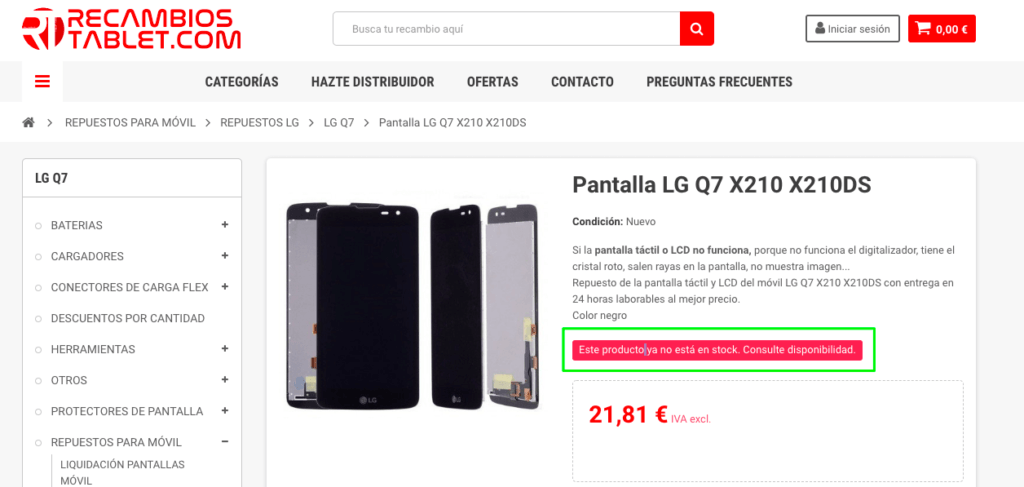
Anyway, I strongly advise you to speak with your client, as you can have several texts displayed in such a situation.
Step 2: Copy the text. Use the source code and not the Inspect element because, by default, Screaming Frog will use it.

Step 3: Open Screaming Frog and use the “Custom Search” functionality. Paste the text that you copied in the previous step.


Step 4: You can start the crawl and wait for it to finish. You’ll then have a complete list of out of stock products. Isn’t it marvellous?

It’s important to review the URLs list given by Screaming Frog to ensure that it doesn’t include any false positive. You can also use the “Custom Extraction” functionality to obtain the same outcome.
This process is interesting, but it comes with several drawbacks:
- It is manual, given that we have to configure Screaming Frog, wait until it finishes and export results.
- We have to crawl the whole website when ideally we should crawl only the URLs we are interested in.
To remove these issues, we are going to dive into how to include this process within an automatic checkup executed every week with Python.
Find out of stock products with Python
In this section, we’ll see how you can build a more automatic system with Python. At the end of the day, what we want to end up with is not all out of stock URLs (we can have a lot depending on our E-commerce size) but an out of stock URLs list with a decent amount of incoming traffic during the last weeks.
The process will be the following:
- Extract products URLs with more incoming traffic during the last 4 weeks. We could include revenue as well, but in this example, we won’t.
- Crawl them and extract the stock value.
- Send an email with the out of stock URLs list, ordered by a number of sessions.
Initial configuration
First of all, I’ll detail all the libraries I use in this script:
import ssl
import smtplib
import email
from google2pandas import *
from datetime import datetime
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.base import MIMEBase
from email import encoders
import time
import requests
import pandas as pd
import requests
import datetime as dt
from requests_html import HTMLSession
import xlsxwriter
Some of them are needed to send an email, but the most important ones are the following:
- Pandas to handle data
- Googl2Pandas which I love because it allows us to retrieve data with Google Analytics’ API directly in a DataFrame, to then manipulate them with Pandas. You’ll have to configure API access beforehand if you want it to work correctly.
- Requests and Requests_html to crawl and extract a part of the content using its Xpath.
- xlsxwriter to create XLSX documents.
Extract data with Google2Pandas
To extract Google Analytics data, you can use the following function:
def GetAnalyticsData(ga_id, start_date, end_date):
query = {
'ids': ga_id,
'metrics': 'sessions',
'dimensions': ['landingPagePath'],
'start_date': start_date,
'end_date': end_date,
'filters': ['sessions>0'],
'max_results': 10000,
'sort': ['-sessions']
}
df, metadata = conn.execute_query(**query)
df.columns = ['pagePath', 'sessions']
# Create the full URL again
df.pagePath = 'xxxxxxx' + df.pagePath
# Merge URLs with and without parameters
df.pagePath = df.pagePath.str.replace('\?.*', '', regex=True)
aggregation_functions = {'pagePath': 'first', 'sessions':'sum'}
df_new = df.groupby(df['pagePath']).aggregate(aggregation_functions).reset_index(drop=True).sort_values(by='sessions', ascending=False)
return df_new
What it does:
- Retrieve Top 10.000 landing pages during the period we use, along with the number of sessions for these pages. As you can observe, I added a filter to exclude pages with less than 1 session from the data.
- Build again the full URL (you must update ‘XXXX’ with your domain name) because the path registered by Google Analytics doesn’t include the domain (by default at least).
- We merge data with and without parameters. This trick prevents us from crawling over and over the same URL if the parameters are not actually modifying the content. If that’s not your case, I strongly advise not to include these lines in your code.
You can use more filters and add more metrics if you need to do so. To get to know the variable names used by Google, you can use the official documentation.
I’ll just add a few comments to describe the variable needed for the function to work properly:
- gaid: your view ID
- start_date and end_date must use the YYYY-MM-DD format.
Keep product URLs only
To keep products data only, we have two options based on our situation:
We can identify product URLs with the URL:
If you are lucky enough to work with product URLs with a specific pattern, for example, https://mydomain.es/p/my-product, we can apply a simple filter to exclude them from being crawled.
data = GetAnalyticsData(ga_id, start_date, end_date)
data = data[data['pagePath'].str.contains('/p')]
Fats & easy, we like it! Nevertheless, I won’t lie: you rarely can use this method, and we often have to be more creative.
We can’t identify product URLs with the URL:
In such a situation, there is not only one solution but the main idea is to find something in the source code to ensure that we are looking at a product URL. In the code provided below, we are in a situation where we extract this information from the Data Layer used by Google Tag Manager.
Retrieve stock value for new products
First the code, then the explanation.
urls = data['pagePath']
output = [['pagePath','stock']]
for element in urls:
r = session.get(element)
# Xpath + extracción del page_type
page_type = r.html.xpath('//script/text()')[0]
page_type = pd.Series(str(page_type))
page_type = page_type.str.replace(
'.*dataLayer.*pageType\"\:\"', '',
regex=True).str.replace('\"\,\"pageUrl.*', '', regex=True)
page_type = page_type[0]
if page_type == 'product':
try:
stock = r.html.xpath('//button[@id="add-to-cart"]/text()')[0]
except:
stock = 'Error extrayendo los datos'
output.append([element,stock])
i += 1
print('Success for element ' + str(i) + ' out of ' + str(len(urls)))
final = pd.DataFrame(output[1:],columns=output[0])
final = final.merge(
data, on='pagePath', how='left')
final = final.sort_values(by=['sessions'])
# Create a Pandas Excel writer using XlsxWriter as the engine.
writer = pd.ExcelWriter('output.xlsx', engine='xlsxwriter')
final.to_excel(writer, sheet_name='data')
# Close the Pandas Excel writer and output the Excel file.
writer.save()
- First, we create the ‘URLs’ variable, which is a list of URLs we’ll be crawling.
- We crawl them one by one (our script doesn’t handle multiprocessing) and if the pageType from the DataLayer matches with ‘product’, we extract the stock value with the Xpath indicated.
- We create a table with the following structure:
| URL | STOCK |
| https://ww.mydomain.es/product-1 | In Stock |
We’ll merge it with our initial table, which uses the following structure….
| URL | Sessions |
| https://ww.mydomain.es/product-1 | 1456 |
… to obtain the following final table:
| URL | Sessions | Stock |
| https://ww.mydomain.es/product-1 | 1456 | In Stock |
If you think about it, we just did a Vlookup 🙂
- Finally, we save the results in an Excel document. We could save only out-of-stock results but in this case, we decide to save the full output.
Send the email
This part of the code is maybe the most important because that’s what allows us to automate the whole process. Indeed, if we upload our script to a server and we create a CRON job to execute it every other week, for instance, we’ll receive the email once the process is executed. Great, isn’t it?
For more information on this part, I strongly advise you have a closer look at https://realpython.com/python-send-email/ from where I got the code I use. I have data-oriented skills in Python, hence the email part is not the one I master the most.
Conclusion
As you have understood, we have several methods to extract stock value from our E-commerce. Without taking into account the one you decide to go with, I strongly advise you to watch it closely from times to times, because you can’t sell anything if you don’t have stock.
