
En este artículo, os quiero explicar lo que es el web scraping y cómo lo podemos usar para el SEO.
Aviso de que no os voy a explicar cómo copiar el contenido de uno de vuestros competidores y colgarlo en vuestra web. Si estáis buscando un tutorial sobre eso, éste no es vuestro artículo.
¿Qué es el web scraping?
Primero. definamos el concepto de web scraping: es una técnica que usamos para extraer información de una o varias páginas webs. En español, podemos usar la palabra “extracción de datos”, que es la más parecida.
¿Cuáles son los usos del web scraping para un SEO?
Existen varias situaciones en las que podemos usar el scraping para ayudarnos. Obviamente, no las voy a explicar todas, pero me enfocaré en dos casos concretos:
- Marketing de contenidos: podemos usar el web scraping para obtener un listado de todos los contenidos generados por un competidor o un portal equivalente. En este caso, no nos interesa copiar el contenido, sino únicamente obtener un listado de los artículos generados para establecer nuestro propio calendario editorial
- Mejoras SEO: podemos scrapear nuestros propios datos para aplicar mejoras SEO o detectar problemas. Más detalles más adelante en este artículo.
Scraping de un listado de contenidos
Para este ejemplo, imaginemos que quieres scrapear el listado de los últimos artículos de https://builtvisible.com/blog/, un blog en inglés que me encanta. Si no lo conoces, te aconsejo que le eches un vistazo.
Elección de la herramienta
Existen varias herramientas que nos permiten llevar a cabo esta extracción de datos. Sin embargo, elegiré Google Drive, ya que dispone de la función IMPORTXML.
Además, de este modo obtendré un resultado dinámico, es decir, que se actualizará cada vez que abra el documento.
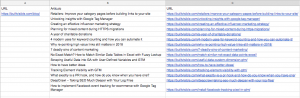
Elección de los datos que queremos scrapearEn mi ejemplo, los datos que necesitamos son:
- El título del artículo
- El enlace del artículo
Para indicar a la fórmula lo que tiene que scrapear, tengo que encontrar el Xpath de cada uno de estos elementos. El Xpath es un lenguaje que nos permite identificar uno o varios elementos de un documento HTML. Por ejemplo:
- //h3 para extraer todos los elementos H3 de un documento
- //h3[1] para extraer el primer elemento H3 de un documento
En nuestro ejemplo del blog de Built Visible, los nombres de los artículos son enlaces que se integran dentro de una etiqueta H3, por lo tanto:
- Título de los artículos: //h3/a (extrae el anchor del enlace)
- URL de los artículos: //h3/a/@href (extrae el atributo href de la etiqueta <a>)
Resultado de nuestra extracción:
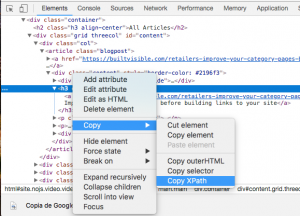
Cabe destacar que puedes extraer el Xpath de un elemento HTML usando el navegador Google Chrome.
- Hacer clic en el botón derecho e inspeccionar
- Seleccionar el elemento HTML que te interesa, hacer clic de nuevo en el botón derecho, después Copiar y, finalmente, Copiar Xpath
Ten en cuenta que, haciendo esto, vas a copiar el Xpath único del elemento, cuando a veces nos interesa un Xpath un poco más genérico para extraer todos los elementos similares, como en mi ejemplo con los nombres de los últimos artículos del blog de Built Visible. En este caso, tendrás que cambiar un poco lo que da Chrome. Si tienes conocimientos básicos de HTML, el lenguaje Xpath no será tan complicado.
Este ejemplo es bastante simple y funciona para una sola página. En caso que quieras extraer el mismo elemento de un conjunto de páginas, te aconsejo usar la funcionalidad Custom Extraction de la herramienta favorita de los SEO, Screaming Frog.
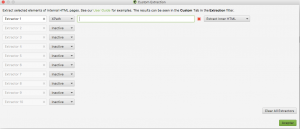
El principio es el mismo: la herramienta extraerá todos los elementos que corresponden al XPATH que le indicas para todas las páginas que rastreará. Para sacar un listado de todos los posts de un competidor y usarlo para crear tu propio calendario editorial, es muy útil.
Mejoras SEO
También podemos usar el web scraping para auditar nuestra página y/o plantear mejoras en nuestro portal. Aunque las posibilidades sean infinitas, voy a explicar dos casos concretos que puedes usar. Para ambos casos, usaremos la extensión: Scraper
Scrapear los resultados «Otras personas también buscan»
Como ya sabrás, desde algunas semanas y en el caso que un usuario tire rápidamente para atrás después de haber hecho clic en unos de los resultados de Google, el motor de página muestra una sección de “Otras personas también buscan”.
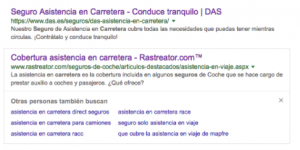
¿Por qué nos interesa recuperar esta información? Simplemente porque Google considera que nuestra búsqueda y estas palabras claves están vinculadas y, por tanto, nos puede interesar usarlas en nuestro contenido (aunque algunas veces sean de marca). Un detalle importante es entender que estas búsquedas se cargan por defecto en el código de la página de resultados de Google y que, por ende, las podemos scrapear después de realizar una búsqueda.
Ejemplo con la búsqueda “cursos SEO”:
- Realizar la búsqueda en Google
- Abrir la extensión Scraper
- Introducir el siguiente código Xpath para la
extracción: //div[contains(@ id,’eobd_’)]/div
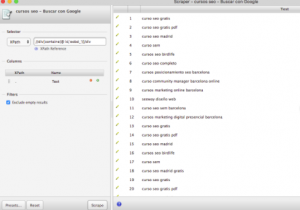
Como he mencionado anteriormente, no siempre nos interesan las palabras claves, pero es interesante entender el vínculo que puede tener una búsqueda con otra para la optimización del contenido.
Detectar imágenes sin texto alternativo
Aunque existan herramientas como Screaming Frog que también pueden hacerlo, es recomendable comprobar que todas las imágenes de una página web cuenten con un texto alternativo definido.
Seguir los siguientes pasos:
- Abrir una página web
- Abrir Scraper
- Copiar la siguiente configuración
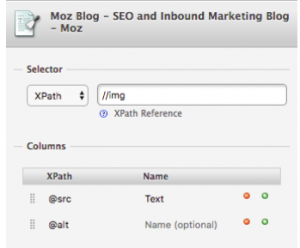
Obtendremos como resultado un listado de imágenes con el texto alternativo asociado, lo que nos permitirá detectar de manera muy eficiente los documentos que carecen de este atributo.
Obviamente, se trata de unos usos que podemos hacer de la extracción de datos de las páginas web. Existen sistemas más complejos, como artoo.js, phantom.js y muchos más. Cada uno tiene sus ventajas e inconvenientes, pero creemos que Screaming Frog y la extensión de extracción de datos de Chrome permiten.
