
Using APIs to connect Google Search Console with ScreamingFrog
This is the second guide on Google Search Console (GSC). While the former one was focused on using Search Console for keyword analysis this article focuses on using the tool to perform a technical SEO audit of your domain.
As Olga Zarr described in her article it’s possible to audit your domain using only GSC.
This can be done using the features listed in GSC
However the beauty of APIs is to allow you to pull several data together. Using GSC with a crawler such as ScreamingFrog (SF) enables you to get a broader overview of any technical issue and optimization. ScreamingFrog has an article along with a video explaining how to connect to the Google Search Analytics and URL Inspection APIs and pull in data directly during a crawl.
Note: Structured Data will be covered extensively and separately in another article.
Indexing pages vs. not indexed ones
Pages
Check the number of your HTML indexable pages in SF against the indexed pages in GSC. Export both lists and compare them in an excel sheet to identify which URLs GSC is not indexing, ask yourself if they are valuable and you want them indexed.
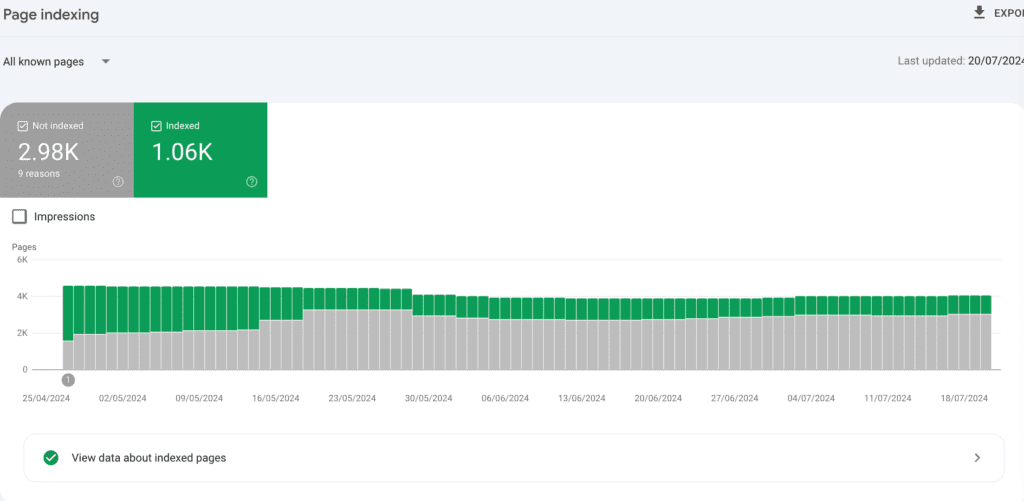
Don’t worry if there are pages that are not indexable: every domain has non indexed pages in their GSC. What you want to ensure is that there are no valuable pages that are left without being indexed.
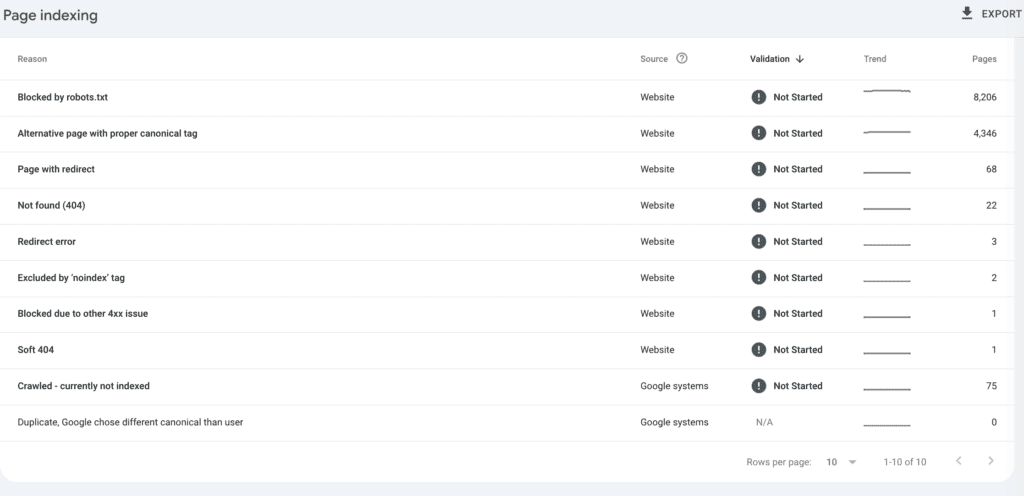
Furthermore, check the list of non-indexed and the reasons for not being indexed. For the URLs listed as Page with redirect and Not found (404) open your crawl in SF and go to Bulk Exports > Response Codes > and export the 4xx and 3xx Report. In this way you will identify where the links are coming from that point to your 3xx and 4xx URLs. Being able to find where these links are linked from enables you to know how the bot is finding these links and to remove these links.
Pay special attention to “Crawled – currently not indexed” you might find there parameter URLs you can exclude from crawling by editing your robots txt. However if you have valuable URLs that should be indexed there and are not you might want to review your content quality. One of the most frequent issues leading to not indexed pages is low quality: refresh your content while ensuring that there are internal links with the right anchor pointing to the URL.
Keep in mind that as stated by John Mueller “it’s normal for 20% of a site to not be indexed”.
Videos
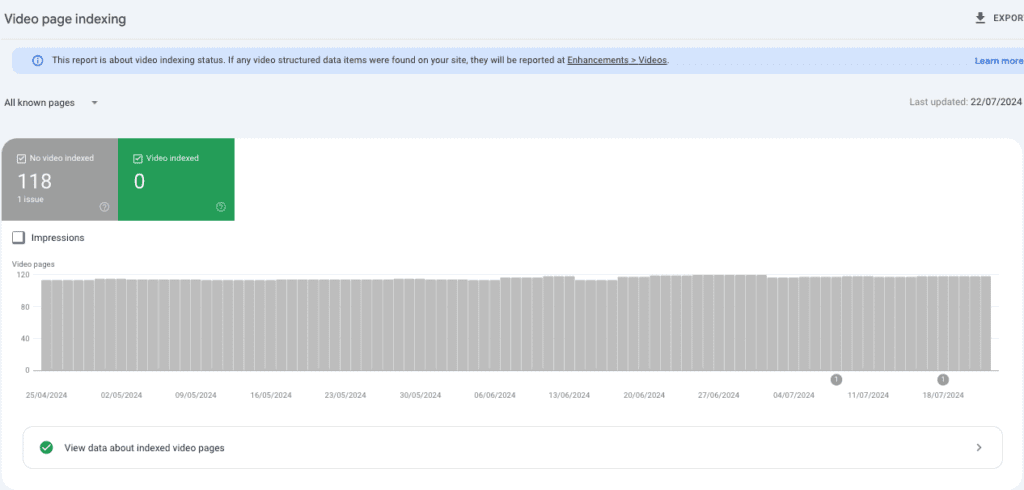
It happens very often that GSC reports “Videos in pages aren’t indexed”
with the reason “Video is not the main content of the page”.
From December 2023 Google documentation changed to state “Videos that aren’t the main content of the page will appear as “No video indexed” in Search Console.”
Hence, assess if on your pages the video is the main content of the page, if not it is likely it won’t be indexed, as stated by Google documentation.
Sitemaps
Before crawling with SF, use the sitemap URL to add it to the crawler. SF will help you analyse errors on your sitemap URLs such as if you have non 200 https URLs on your sitemap.
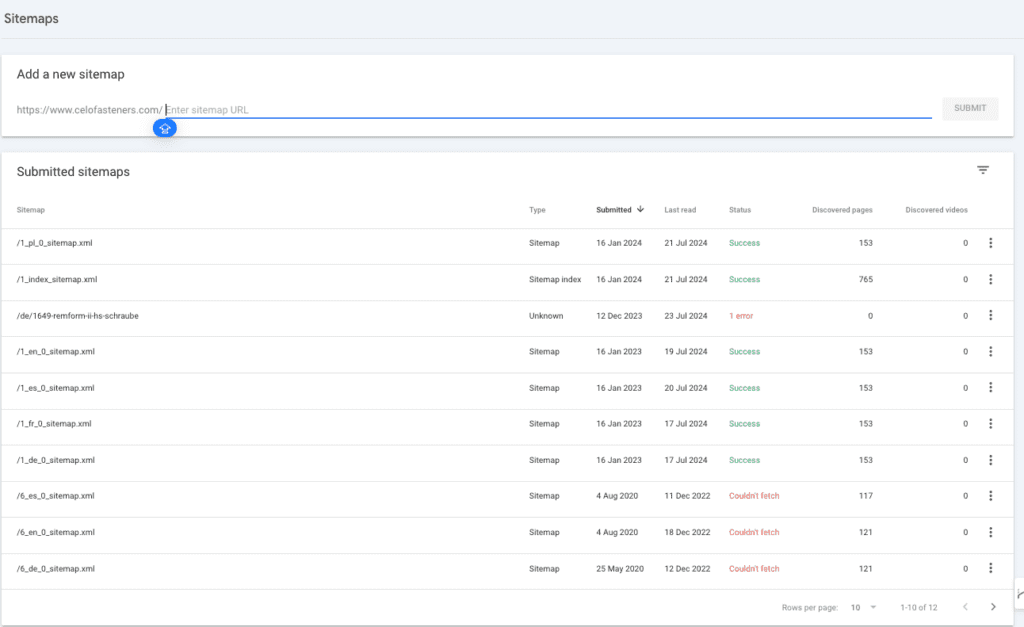
GSC will enable you to know if there is any error fetching the sitemap. Open and check the sitemaps and complement SF to audit your sitemap. If you have several sitemaps which might have been added over time, remove the old ones and unnecessary ones.
Removals
In my experience I have never seen any Google notification on the Removal section. This section can also be used to remove your site URLs from the index. ContentKing has a complete article on “How to Remove URLs from Google Search Quickly”.
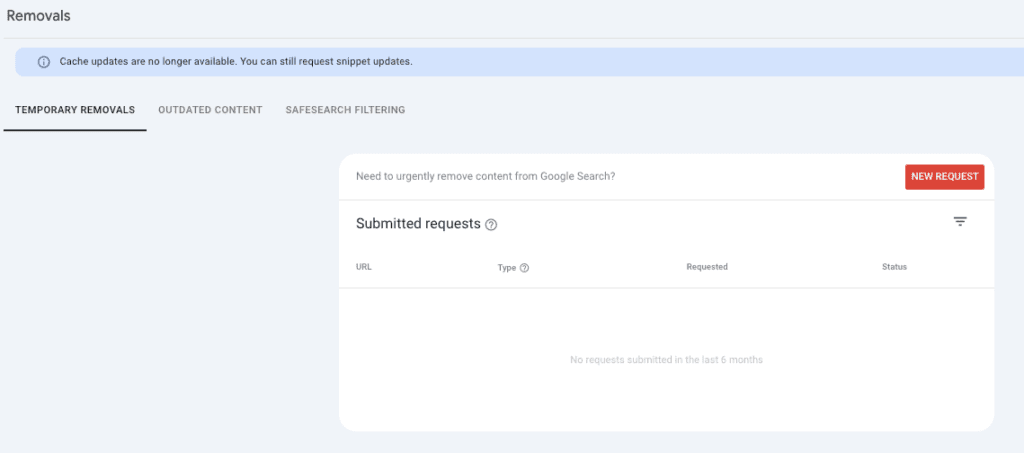
Once you are just starting to audit the domain for the first time, this section should be checked to determine if any of these requests have been submitted, and if so, to understand the intent behind them.
Page experience
As stated by Rick Viscomi from the Chrome Web Performance team on the 71st EPISODE of the podcast “Search Off The Record” the main difference that should be kept in mind for Core Web Vitals is that the data in GSC is the field data describing real users experience with the domain. Hence, when you analyse the performance of a URL on your computer keep in mind your users might have a different experience in terms of page performance than the one you are seeing both in terms of experience and proper Core Web Vitals values.
Hence, as Rick Viscomi says, while only your Core Web Vitals (CWV) performance won’t lead to a drop in your site traffic, on the other side this data should be fully analysed. And field data of your users should be given more prominence over lab data (your CWV testing on your laptop).
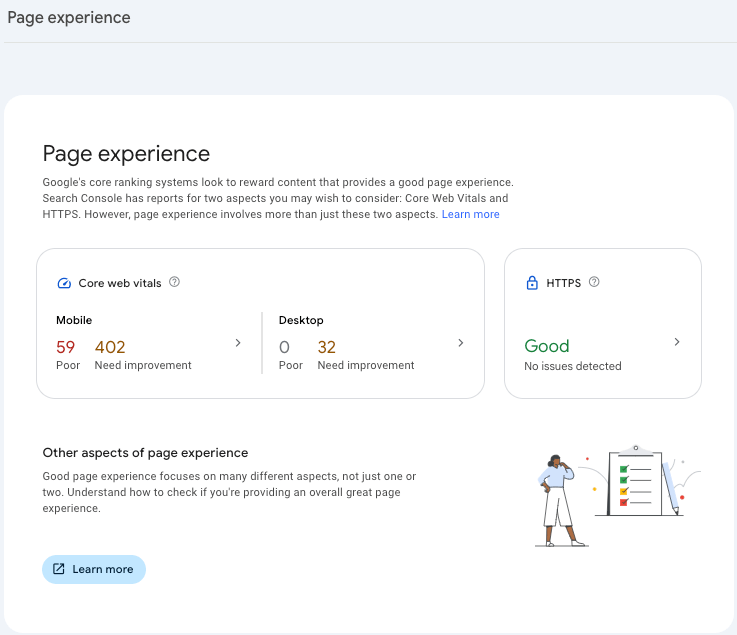
The Page Experience section allows you to know what is the user experience when they navigate in your site: is it fast? Do they have elements and images moving all along the page while they wait for the page to load (which would denote a Content Layout shift issue)?
Page experience and Core Web Vitals
The first section, the one named “Page Experience” gives you an overview of the CWV. Either from there or from the following section, the one called Core Web Vitals, you can dig deeper into mobile and desktop performance.
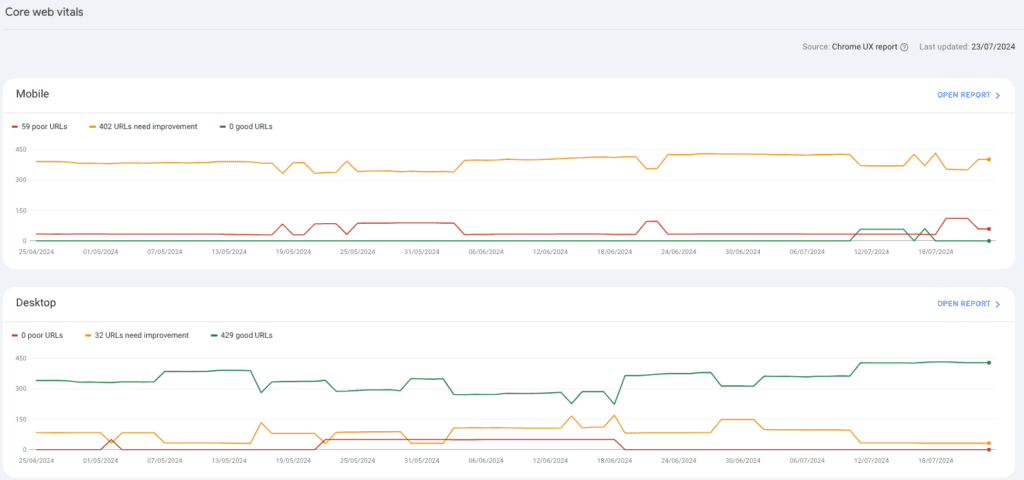
If there are poor URLs, open the report, select the issue and check the URLs in this group. Pay attention to whether all the URLs belong to the same template, if so you might want to talk to your dev team to assess the issue at a template level.
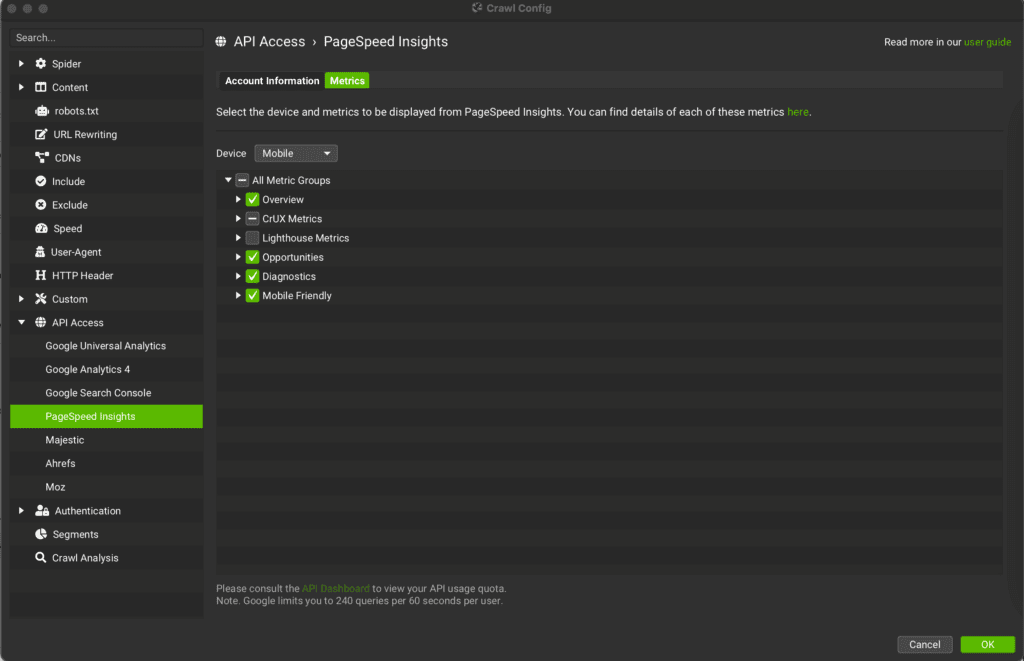
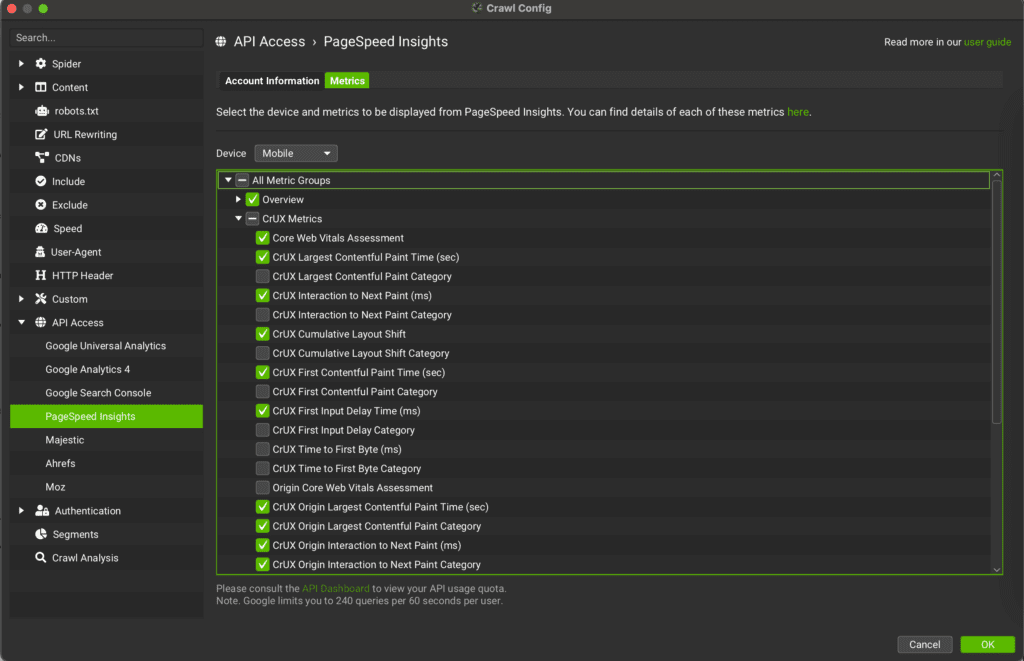
Meanwhile use SF settings to get more data crawling to the domain. To do so, go to SF, select “API Access” and connect “Page Speed Insights”. Based on the issues reported by GSC select the data in “Metrics”. What should be selected are the CrUX (field data) metrics related to the issue you have spotted in GSC.
HTTPS
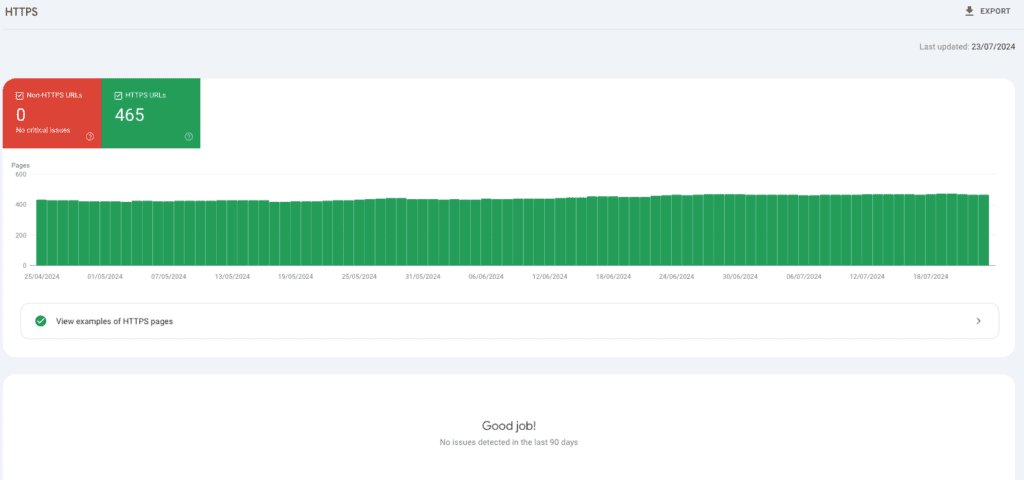
Although in my experience I have never come across any domain who had this section flagged with non https URLs, if you find any non https URL you should immediately ensure to solve this issue. This will also be flagged by SF, which beside the HTML URLs will also flag any other URL, whether image or any other element non https. All the URLs should be https: users won’t trust a non https and Google will flag it to users if they land on it.
Links
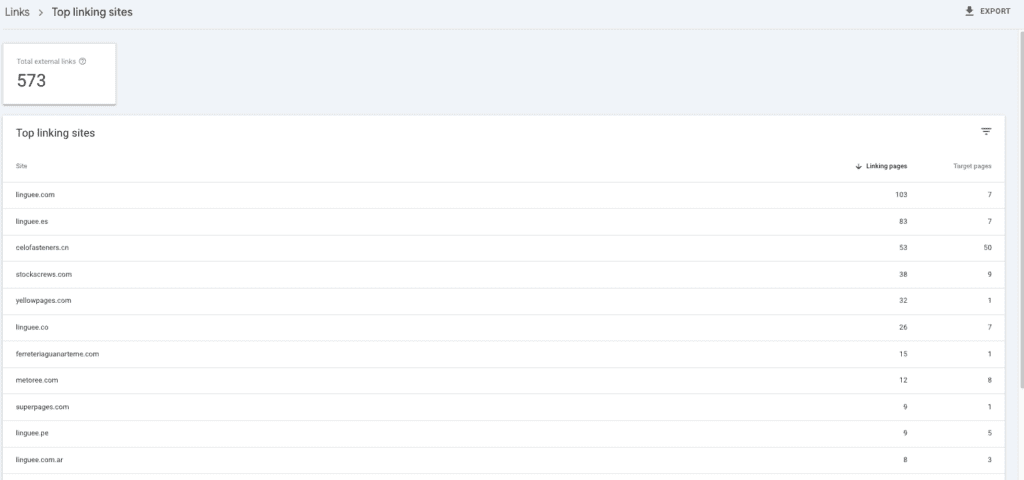
Based on my experience the links section while it’s worth checking can be analysed in a deeper way with crawlers. The only advice is to check the Top linking sites to ensure there are no spammy domains there.
Settings
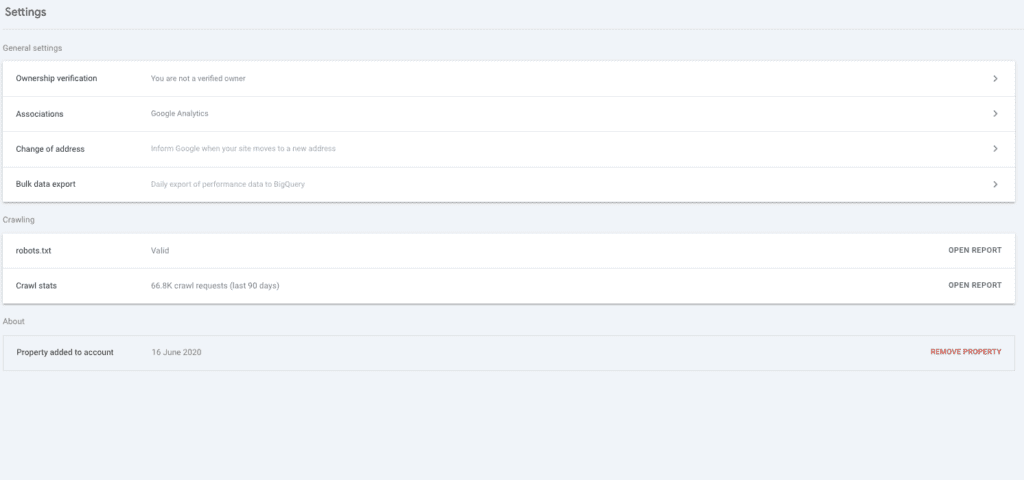
This is one of the most important parts of GSC and should be checked regularly, the 2 relevant parts of it are:
- Robots.txt
- Crawl stats
Robots.txt
Open the report, ensure the Status of the robots txt is “Fetched”, if this is not the case, review immediately the txt file to understand what is happening and give maximum priority to solve it.
Open the link of your robots txt file from there and review it. As a tip, copy and paste the content into another text or word document. Then go to SF and review a pool of your blocked by robots pages. If there are pages you consider relevant and want to see crawled, edit the document where you copied your robots txt file.
Paste the new version of your robotSF TXT in SF, in the omonimous section and paste a URL in the raw called “Test”. This will enable you to understand the changes made to the robots txt and how they will impact bots behaviour.
As Mark Williams-Cook, founder of AlsoAsked, explained “Contrary to popular belief, adding pages to robots txt does _not_ stop them from being indexed. Robots txt controls crawling, not indexing.” Keep this in mind while working on your txt file and while auditing your domain.
Crawl stats
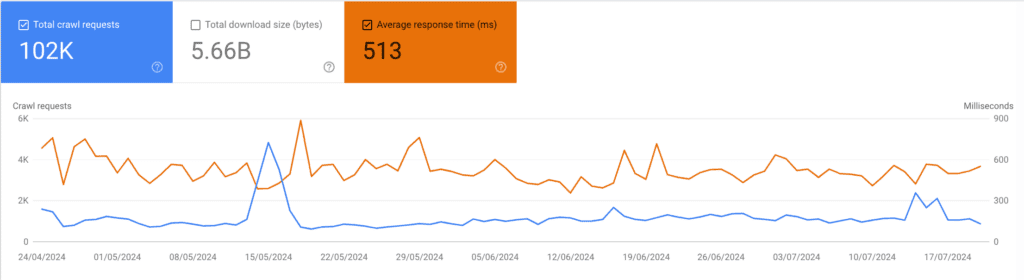
In the crawl stats report select the Average Response Time. What should concern you are:
- Increasing Average Response Time: if there is a clear spike up from one date ensure by asking to the developer team if a server migration was made on the same day of the spike. Or if any template or plugin was added to the CMS. Remember: the time of the response is measured by Googlebot from the US. Hence if there was a server migration to a Server in another country to ensure users in the target country will get better performance you might parallely notice a decrease in the Average Response Time. In summary you want to lower as much as you can the Average Response Time.
- Decreasing Total Crawl Request: dig deeper to understand which file and response type is the one that has led to less crawl request. If your site is not updating the content it might be that Google is checking it less often. You should aim at enhancing crawl frequency to give a signal of fresh content to Google.
If during the same day the Average Response Time increased abruptly while your Total Crawl Request decreased it’s possible that Google have crawled your site and found it slow either because of a DDOS attack or either because it was slowed down by several users at the same time. In any case, you want to ensure this does not happen again. Googlebot might start crawling your site to avoid overloading it, however this will mean the bot will notice with less frequency updated content and it will take longer to index new content.
Final thoughts
If you want to get a broader overview on how GSC works Anna Crowe recently published an article on Search Engine Land.
While GSC offers valuable insights, combining it with SF allows for a more comprehensive analysis. SF crawls your website, identifying technical issues that GSC might miss.
In conclusion, while Google Search Console offers a wealth of SEO data, using it alongside Screaming Frog unlocks a more powerful technical SEO audit. By combining GSC’s insights with SF’s crawling capabilities, you gain a comprehensive view of your website’s health, identifying and addressing potential issues that could be hindering your search engine ranking.
